Blick in das CERN Computing Centre
Foto: CERN

20.01.2011
Der LHC-Datenhighway

Der LHC-Datenhighway

Riesig Datenmengen entstehen bei den Experimenten am LHC – bis zu 15 Petabyte pro Jahr! Und diese Daten müssen nicht nur gespeichert werden, sondern Wissenschaftler aus der ganzen Welt wollen auf diese Daten zugreifen und sie auf verschiedene Dinge – wie zum Beispiel neue, unbekannte Physik – untersuchen. „Schon bei den Planungen für den LHC war klar: wir wollen verteilt rechnen“, erklärt Günter Duckeck. Der Wissenschaftler von der LMU München koordiniert das Grid für die deutschen ATLAS-Wissenschaftler und ist ein Mann der ersten Stunde.
„Verteiltes Rechnen gibt es schon länger, wenn auch deutlich anders“, erzählt er. Zu der Zeit seiner Diplomarbeit in Heidelberg wurden zum Beispiel die Daten, die bei Experimenten bei DESY in Hamburg genommen wurden, kopiert und von den Wissenschaftlern, die am Wochenende nach Hause nach Heidelberg fuhren, mitgenommen. Montags konnten die Bänder dann im Rechenzentrum in Heidelberg eingelegt werden.
Heute heißt verteiltes Rechnen: die Programme laufen nicht vor Ort auf dem eigenen Rechner, sondern werden in einem der vielen Rechenzentren, die das Grid bilden. Dieser ganze Vorgang läuft weitgehend automatisiert und für den Nutzer unsichtbar. Besonders spannend an dem Konzept des Grid findet Duckeck, dass man nie genau weiß, wo denn gerade das eigene Programm gerade ausgeführt wird. „Ich kann zwei Tage hintereinander das gleiche Programm ins Grid schicken: Den einen Tag wird es in Japan, am nächsten in den USA bearbeitet. Je nachdem, wo es gerade schneller geht. Und im Idealfall bekomme ich nichts davon mit!“, erzählt er begeistert.

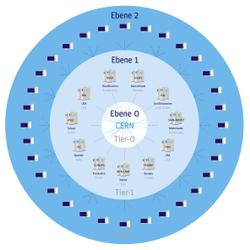
Baumstruktur des Grids
Doch das Grid wird nicht nur zum „Rechnen“ genutzt, sondern speichert auch die am LHC genommenen Daten. Um den Datenmengen Herr zu werden, verfügt das Grid über eine Baumstruktur. Die oberste Ebene bildet das Rechenzentrum direkt am CERN – das so genannte Tier 0. Hier werden die Rohdaten direkt in der Form gespeichert, in der sie auch bei den Detektoren am LHC genommen werden. Die bereits aufgearbeiteten Daten werden in der nächsten Ebene, den Tier 1 gespeichert. Elf solcher Zentren gibt es weltweit. In der nächsten Ebene gibt es über den ganzen Globus verteilt mehr als 80 Tier 2-Zentren. Auf diese Ebene folgen dann noch die Zentren der einzelnen Institute über die dann die Nutzer ans Grid „angeschlossen“ sind.
Die Struktur, die das Grid bietet, ist nicht nur für die Daten des LHC gut geeignet. Auch für andere Gebiete, wie in der Biologie, bietet das Grid viele Möglichkeiten, um die riesigen anfallenden Datenmengen zu bewältigen. Und vielleicht ist es eines Tages so weit, dass das Grid den Weg in unseren Alltag findet.